



What is Pub-Sub?
Pub/Sub messaging enables you to create an event-driven systems consisting of event producers and consumers, called publishers and subscribers. Publishers asynchronously broadcast the events to communicate, rather than by synchronous remote procedure calls (RPCs), in which publishers must wait for subscribers to receive the data. However, the asynchronous integration in Pub/Sub increases the flexibility and robustness of the overall system.
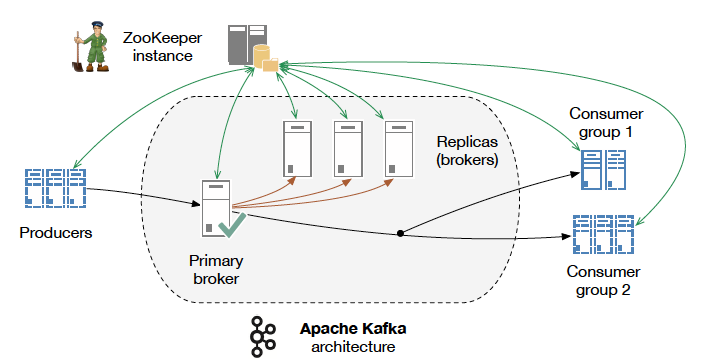
Kafka Architecture Source: kth.diva-portal.org/smash/get/diva2:813137/..
Apache Kafka
Apache Kafka is the open-source stream processing software platform, which is written in Scala and Java. Apache Kafka is a fast, scalable, fault-tolerant messaging system which enables communication between producers and consumers using message-based topics. Kakfa is highy resilient of node failures and support auto-recovery. This makes Apache Kafka ideal for communication and integration between components of large-scale data systems in real-world data systems.
Brokers
Kafka consists of a network of machines called brokers. these may not be separate physical servers but containers running on pods running on virtualized servers running on actual processors in a physical datacenter somewhere. However they are deployed, they are independent machines each running the Kafka broker process. Since, there can be multiple brokers there needs to be a central service which keeps track of all the states and configurations of all kafka brokers, hence we introduce zookeeper.
Zookeeper
Kafka and ZooKeeper work in conjunction to form a complete Kafka Cluster. With ZooKeeper providing the distributed clustering services, and Kafka handling the actual data streams and connectivity to clients. At a detailed level, ZooKeeper handles the leadership election of Kafka brokers and manages service discovery as well as cluster topology so each broker knows when brokers have entered or exited the cluster, when a broker dies and who the preferred leader node is for a given topic/partition pair. It also tracks when topics are created or deleted from the cluster and maintains a topic list.
Kafka logging Mechanism:
Kafka is based on commit log, which means Kafka stores a log of records and it will keep a track of what’s happening. This log storage mechanism is similar with common RDBMS uses. The mechanisms is more like a queue where you always append a new data into the tail. It may seems simple, but Kafka can maintain the records into several partitions with same topic. A topic is a category or feed name to which records are published. So, rather than just write into one queue, Kafka can writes into several queue with same topic name.
Basic Pub-Sub Application using kafka and golang
Setup Kafka using Docker
Here is the docker-compose.yaml used to setup kafka:
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- 9093:9093
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CREATE_TOPICS: my-kafka-topic
In this docker-compose file kafka image used is:
confluentinc/cp-kafka:latest
And the zookeeper image used is
confluentinc/cp-zookeeper:latest
Since it is a basic pubsub we would be using only one broker instance and the topics created is: my-kafka-topic
Now since the kafka image has been set up now we need to define publishers and consumers.
This will be done using go-library:
github.com/segmentio/kafka-go
The main part of publishing message into Kafka is you must create the connection into Kafka then you can produce a message to Kafka using established connection. For this we will be creating kakfa-writer function in which we define all the kafka configurations and establish connections to kafka.
func getKafkaWriter(kafkaURL, topic string) *kafka.Writer {
return &kafka.Writer{
Addr: kafka.TCP(kafkaURL),
Topic: topic,
Balancer: &kafka.LeastBytes{},
}
}
After the kafka connection is established, the kafkaWriter object can be used to broadcast data from publisher. Below is the basic golang producer Method we have implemented:
func producer(kafkaWriter *kafka.Writer, ctx context.Context) {
var body string
for {
fmt.Scanf("%v", &body)
msg := kafka.Message{
Key: []byte(fmt.Sprintf("address-%s", broker1Address)),
Value: []byte(body),
}
err := kafkaWriter.WriteMessages(ctx, msg)
if err != nil {
log.Fatalln(err)
}
}
}
In this we have created a message object which have a key value structure and we are sending the message via kafkaWriter object we have implement earlier.
Once the message is published the consumer who is subscribed to same topic to which kafka broker is configured can recieved it. Below is the basic golang consumer method we have implemented:
func consume(ctx context.Context, group string) {
r := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{broker1Address},
Topic: topic,
GroupID: group,
})
for {
msg, err := r.ReadMessage(ctx)
if err != nil {
panic("could not read message " + err.Error())
}
fmt.Printf("%v received: %v", group, string(msg.Value))
fmt.Println()
}
}
Here we have implemented a kafka reader object with same configuration and topics as kafka broker to establish connection with kafka and recieve messages.
Below is the main() function for the produce and consumer
func main() {
ctx := context.Background()
go producer(getKafkaWriter(broker1Address, topic), ctx)
go consume(ctx, "grp2")
time.Sleep(time.Minute * 2)
}
Below is the output of above-mentioned code
GOROOT=/home/manubhav/sdk/go1.18 #gosetup
GOPATH=/home/manubhav/go #gosetup
/home/manubhav/sdk/go1.18/bin/go build -o /tmp/GoLand/___go_build_pub_sub pub-sub #gosetup
/tmp/GoLand/___go_build_pub_sub
Hello
grp2 received: Hello
World
grp2 received: World
Process finished with the exit code 0
Strengths of Kafka
a. High-throughput
Without having not so large hardware, Kafka is capable of handling high-velocity and high-volume data. Also, able to support message throughput of thousands of messages per second.
b. Low Latency
It is capable of handling these messages with the very low latency of the range of milliseconds, demanded by most of the new use cases.
c. Fault-Tolerant
One of the best advantages is Fault Tolerance. There is an inherent capability in Kafka, to be resistant to node/machine failure within a cluster.
d. Durability
Here, durability refers to the persistence of data/messages on disk. Also, messages replication is one of the reasons behind durability, hence messages are never lost.
e. Scalability
Without incurring any downtime on the fly by adding additional nodes, Kafka can be scaled-out. Moreover, inside the Kafka cluster, the message handling is fully transparent and these are seamless.
f. Distributed
The distributed architecture of Kafka makes it scalable using capabilities like replication and partitioning.
g. Message Broker Capabilities
Kafka tends to work very well as a replacement for a more traditional message broker. Here, a message broker refers to an intermediary program, which translates messages from the formal messaging protocol of the publisher to the formal messaging protocol of the receiver.
h. High Concurrency
Kafka is able to handle thousands of messages per second and that too in low latency conditions with high throughput. In addition, it permits the reading and writing of messages into it at high concurrency.
i. Consumer Friendly
It is possible to integrate with the variety of consumers using Kafka. The best part of Kafka is, it can behave or act differently according to the consumer, that it integrates with because each customer has a different ability to handle these messages, coming out of Kafka. Moreover, Kafka can integrate well with a variety of consumers written in a variety of languages.